Introduction
Deploying Kubeflow on cloud can transform your AI and machine learning workflows. At aiblux, we specialize in crafting tailored, client-centric solutions that harness cutting-edge technology. In this guide, we will explore the step-by-step process of deploying and managing Kubeflow deployment on cloud, ensuring a seamless, efficient, and scalable experience.
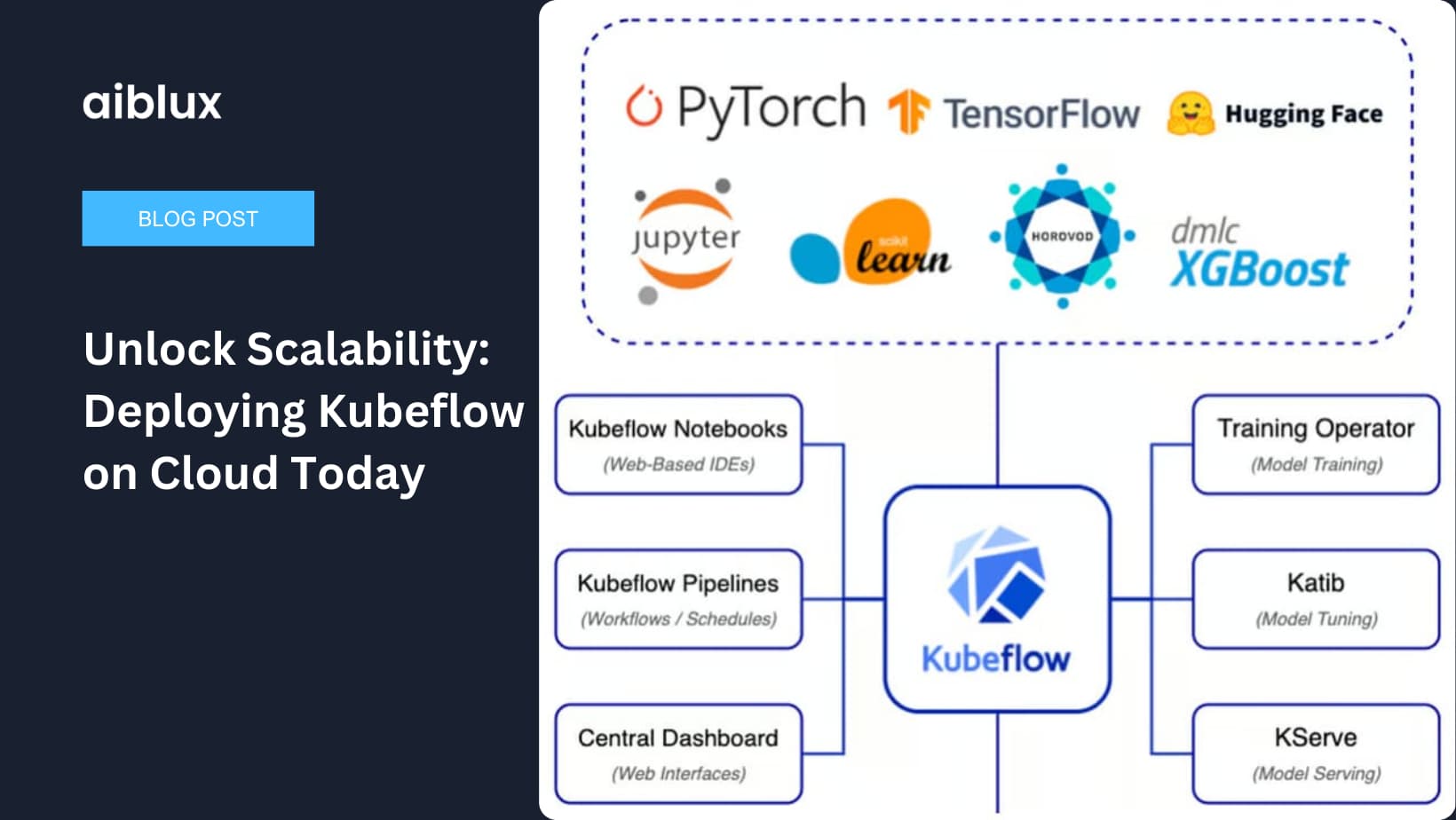
Understanding Kubeflow and Its Importance
Kubeflow is an open-source platform designed to make machine learning (ML) workflows on Kubernetes simple, portable, and scalable. By deploying Kubeflow on the cloud, you can take advantage of cloud computing’s flexibility, scalability, and cost-effectiveness, ultimately driving your business forward with impactful strategies.
Prerequisites for Kubeflow Deployment
Before we begin, ensure you have the following prerequisites:
- A cloud account (AWS, GCP, or Azure)
- Kubernetes cluster set up in your cloud environment
- Kubectl installed and configured
- Basic understanding of Kubernetes and cloud services
Step-by-Step Kubeflow Deployment
Step 1: Set Up Your Cloud Environment
First, set up a Kubernetes cluster on your preferred cloud provider. Ensure it meets the resource requirements for running Kubeflow. This includes configuring nodes, storage, and networking.
Step 2: Install Kubeflow
- Download and Configure Kubeflow: Clone the Kubeflow manifests repository from GitHub.
git clone https://github.com/kubeflow/manifests.git
cd manifests- Deploy Kubeflow: Use the kfctl tool to deploy Kubeflow.
kfctl apply -V -f kfctl_k8s_istio.yamlThis will deploy the necessary components, including Jupyter notebooks, TensorFlow Serving, and more.
Step 3: Configure Authentication and Access Control
Secure your Kubeflow deployment by setting up authentication and access control. Configure Identity-Aware Proxy (IAP) for OAuth-based authentication.
Step 4: Setting Up Persistent Storage
Integrate persistent storage to retain your data and model artifacts. Configure Persistent Volume Claims (PVC) to manage your storage requirements effectively.
Step 5: Deploying Your ML Pipeline
- Create a Pipeline: Use the Kubeflow Pipelines SDK to define your ML pipeline.
import kfp
from kfp import dsl
@dsl.pipeline(
name='Sample Pipeline',
description='An example pipeline'
)
def sample_pipeline():
pass
kfp.compiler.Compiler().compile(sample_pipeline, 'sample_pipeline.yaml')- Upload and Run the Pipeline: Upload the pipeline to the Kubeflow Pipelines UI and start an experiment to run it.
Step 6: Monitoring and Logging
Utilize Kubeflow’s built-in tools for monitoring and logging your ML workflows. Tools like Prometheus and Grafana can provide insights into resource utilization and performance metrics.
Best Practices for Managing Kubeflow on Cloud
- Regular Updates: Keep your Kubeflow and Kubernetes versions up-to-date to leverage new features and security patches.
- Scalability Planning: Design your ML workflows with scalability in mind, ensuring your infrastructure can handle increased load.
- Cost Management: Monitor and optimize your cloud resource usage to manage costs effectively.
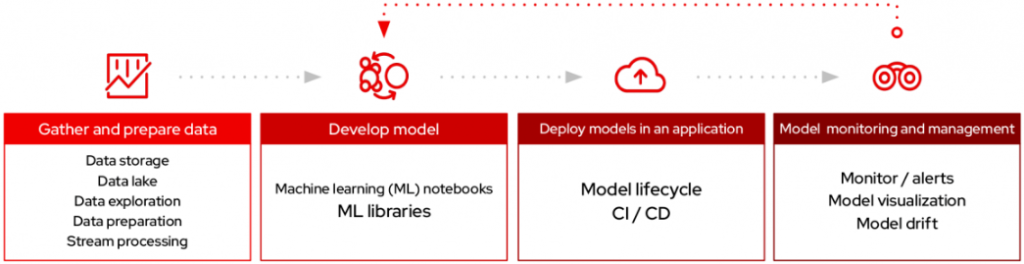
Conclusion
Deploying and managing Kubeflow on the cloud can streamline your AI and ML workflows, driving innovation and efficiency. At aiblux, we are committed to delivering tailored, client-centric solutions that meet your unique business challenges.
Ready to enhance your ML workflows with Kubeflow? Contact us today to explore our services and find out how we can help you achieve your goals. Visit aiblux for more information.