Web Categorization Based on Machine Learning and Deep Learning
Overview
In this project, a web categorization system is developed that leverages machine learning (ML) and deep learning techniques to automatically classify websites into predefined categories. Web categorization is a crucial task for various applications, including search engines, content filtering, and digital marketing. The project involved building a robust pipeline that processes website data, extracts relevant features, and applies ML and deep learning models to accurately categorize websites. The goal was to create a system that could handle the diversity of web content, providing high accuracy and scalability.
Objectives
- Accurate Web Categorization: Develop a system capable of accurately categorizing websites into predefined categories, such as News, E-commerce, Education, Entertainment, etc.
- Feature Extraction: Implement effective methods for extracting meaningful features from website content, including text, metadata, and structural elements.
- Model Development: Utilize machine learning and deep learning models to classify websites, comparing their performance to identify the best approach.
- Scalability and Efficiency: Ensure the system can process large volumes of web data efficiently, making it suitable for real-time or large-scale applications.
- Evaluation and Validation: Evaluate the system’s performance using metrics such as accuracy, precision, recall, and F1-score, refining the model based on results.
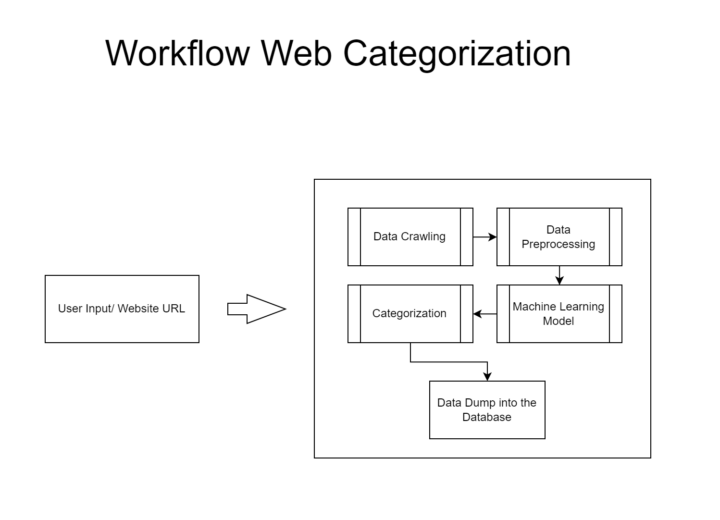
Technical Architecture
Data Collection and Preprocessing:
- Data Sources: The system collects data from various websites, including the HTML content, metadata, and additional sources such as social media links or embedded content.
- Preprocessing: The raw data undergoes preprocessing steps, including text cleaning (removing HTML tags, stop words, etc.), tokenization, and normalization. This step ensures that the data is in a consistent format suitable for feature extraction and modeling.
Feature Extraction:
- Text Features: Text content from the website (e.g., body text, headings, and metadata) is processed to extract features using techniques like TF-IDF (Term Frequency-Inverse Document Frequency) or word embeddings (e.g., Word2Vec, GloVe, BERT).
- Structural Features: The system also extracts structural features such as the number of images, videos, hyperlinks, and the website’s overall structure, which can provide additional context for categorization.
- Metadata Features: Metadata such as page titles, descriptions, and keywords are also extracted and used as features in the categorization process.
Model Development:
- Machine Learning Models: Traditional machine learning models like Support Vector Machines (SVM), Random Forests, and Gradient Boosting Machines are trained on the extracted features. These models are tuned for optimal performance using techniques like grid search and cross-validation.
- Deep Learning Models: Deep learning models such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are implemented to capture more complex patterns in the web content. These models are particularly useful for capturing semantic information from the text.
- Hybrid Approaches: The system also explores hybrid approaches, combining the strengths of both ML and deep learning models to improve overall accuracy and robustness.
Model Training and Fine-Tuning:
- The models are trained on a labeled dataset of websites, with predefined categories used as the target labels.
- Fine-tuning involves adjusting model hyperparameters, selecting the best feature sets, and applying techniques such as dropout and regularization to prevent overfitting.
Model Evaluation:
- The trained models are evaluated on a separate test dataset using metrics such as accuracy, precision, recall, F1-score, and confusion matrices.
- Comparisons between different models (ML vs. deep learning) are made to determine the best-performing approach for web categorization.
Deployment and Integration:
- The final model is deployed as a web service or integrated into an existing application, providing real-time or batch processing capabilities.
- The system is designed to be scalable, capable of handling large datasets and multiple requests simultaneously, making it suitable for commercial applications like search engines or content management systems.
Tech Stack
- Scikit-learn: For implementing and training traditional machine learning models.
- TensorFlow/Keras or PyTorch: For building and training deep learning models.
- NLTK/Spacy: For natural language processing tasks such as tokenization, stop word removal, and text normalization.
- BeautifulSoup/Scrapy: For web scraping and HTML content extraction.
- Pandas/NumPy: For data manipulation, preprocessing, and feature engineering.
- Matplotlib/Seaborn: For visualizing model performance and evaluation metrics.
- Tools:
- Jupyter Notebooks: For experimentation, model development, and documentation.
- Docker: For containerizing the application, ensuring consistency across different deployment environments.
- Git: For version control and collaboration.
- AWS/GCP: For cloud-based training and deployment, ensuring scalability and high availability.
Conclusion
This project successfully developed a comprehensive web categorization system that combines the strengths of both machine learning and deep learning approaches. The system demonstrated high accuracy in categorizing websites into predefined categories, making it a valuable tool for applications that require automatic content classification, such as search engines, content filtering, and targeted advertising.
The project highlighted the importance of effective feature extraction and model selection in building a robust categorization system. By leveraging deep learning models, the system was able to capture complex patterns and semantic relationships within web content, leading to improved categorization performance.
The final solution is scalable and efficient, capable of processing large datasets in real-time, making it suitable for integration into large-scale web applications. This project lays the groundwork for further exploration into more advanced categorization techniques, such as unsupervised learning or reinforcement learning, to handle evolving web content and new categories.
For more information on how aiblux can help you with custom software solutions, contact us or explore our services.