Object Counting and Fine-Tuning Using Florence 2 Model
Overview
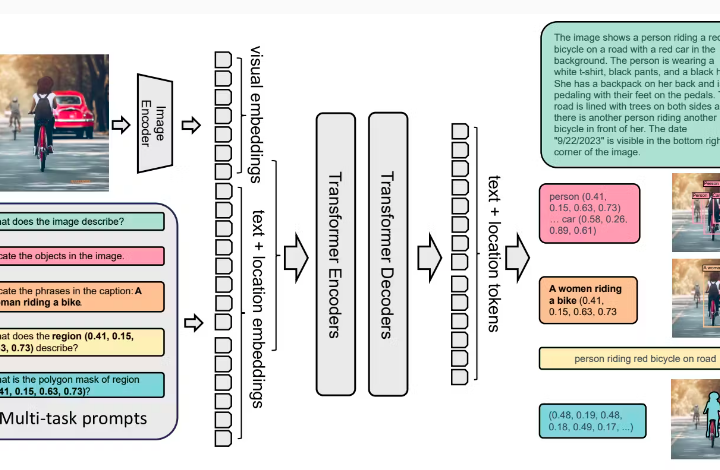
In this project, object counting system was implemented utilizing the Florence 2 model, a state-of-the-art vision transformer-based model known for its robustness in various computer vision tasks. The project focused on accurately counting objects within images and fine-tuning the Florence 2 model to enhance its performance for specific object counting scenarios. Object counting is crucial in many applications, including inventory management, crowd analysis, and environmental monitoring. By fine-tuning the Florence 2 model, the system was adapted to handle different types of objects, improving counting accuracy and efficiency across diverse datasets.
Objectives
- Accurate Object Counting: Develop a reliable system capable of accurately counting objects in images, regardless of object size, shape, or overlap.
- Model Fine-Tuning: Fine-tune the Florence 2 model to optimize its performance for specific object counting tasks, ensuring high accuracy and generalization across various datasets.
- Performance Evaluation: Evaluate the system’s performance using metrics such as Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) to validate its effectiveness.
- Scalability: Ensure that the system can be scaled to handle large datasets and different types of objects, making it adaptable for real-world applications.
Technical Architecture
Data Collection and Preprocessing:
- The system starts with collecting and preparing a diverse dataset containing images with objects to be counted. The dataset may include various categories like people, vehicles, animals, or manufactured items.
- Preprocessing steps include resizing, normalization, and augmentation to enhance the robustness of the model during training. Annotated data with ground truth counts are used for supervised learning.
Base Model Initialization:
- The Florence 2 model, a vision transformer, is initialized as the base model for object detection and counting. Florence 2 is known for its strong ability to capture spatial and contextual information, making it suitable for tasks that require understanding complex scenes.
- Transfer learning is utilized by loading pre-trained weights from the Florence 2 model, which provides a strong starting point for fine-tuning.
Model Fine-Tuning:
- The model is fine-tuned on the specific object counting dataset. During fine-tuning, the model’s layers are adjusted to better understand the particular objects and contexts in the dataset.
- Loss functions such as Mean Squared Error (MSE) or Cross-Entropy Loss (for classification of counts) are used to guide the training process.
- Hyperparameter tuning is conducted to optimize the model’s learning rate, batch size, and other critical parameters to achieve the best performance.
Object Counting Mechanism:
- After fine-tuning, the model is used to predict the number of objects in new images. The prediction process involves the model analyzing the entire image and outputting a count based on the learned features.
- Post-processing techniques may be applied to refine the count, such as removing outliers or correcting for overlapping objects.
Evaluation and Testing:
- The system’s performance is evaluated on a test set using metrics like MAE and RMSE, which provide insights into the accuracy of the counting process.
- Additional testing on unseen datasets is performed to assess the model’s generalization capabilities.
Deployment:
- The final model is deployed within an application framework that can take images as input and output the object count. This application can be integrated into larger systems, such as inventory management or monitoring platforms.
- Scalability considerations are made to ensure the system can handle high volumes of images or video streams in real-time applications.
Tech Stack
- Programming Languages: Python
- Frameworks and Libraries:
- Florence 2 Model: For object detection and counting, fine-tuned for specific tasks.
- PyTorch or TensorFlow: Backend for model training, fine-tuning, and inference.
- OpenCV: For image processing tasks such as resizing, augmentation, and visualization.
- NumPy/Pandas: For data manipulation, preprocessing, and results analysis.
- Matplotlib/Seaborn: For visualizing results and performance metrics.
- Tools:
- Jupyter Notebooks: For experimentation, model training, and fine-tuning.
- Docker: To containerize the application for consistent deployment across environments.
- Git: For version control and collaboration.
- Cloud Platforms (e.g., AWS, GCP): For scalable training and deployment environments.
Conclusion
This project successfully demonstrated the application of the Florence 2 model for accurate object counting through fine-tuning. The ability to fine-tune a pre-trained model like Florence 2 allowed for high performance in specific object counting tasks, addressing challenges such as object overlap, scale variation, and complex backgrounds. The project not only achieved accurate counting but also highlighted the flexibility and power of modern vision transformers in adapting to various computer vision tasks.
The implementation provides a scalable solution for object counting that can be applied in numerous real-world scenarios, from retail inventory management to wildlife monitoring. The fine-tuning approach ensures that the model is tailored to the specific characteristics of the target application, maximizing accuracy and reliability.
This project lays a strong foundation for future work, which could involve extending the system to handle real-time video streams or integrating it with other analytical tools for comprehensive monitoring solutions. Overall, the project represents a significant step forward in leveraging deep learning for practical, high-impact applications in object counting and beyond.
For more information on how aiblux can help you with custom software solutions, contact us or explore our services.


