RAG Based Chatbots
Overview
Our website features a state-of-the-art Retrieval-Augmented Generation (RAG) chatbot designed to deliver accurate and contextually relevant responses by leveraging a sophisticated combination of document chunking, vector storage, and language model predictions. This innovative chatbot integrates seamlessly with PDF documents, providing users with precise information retrieval capabilities for enhanced user experience and productivity.
How the Pipeline Works
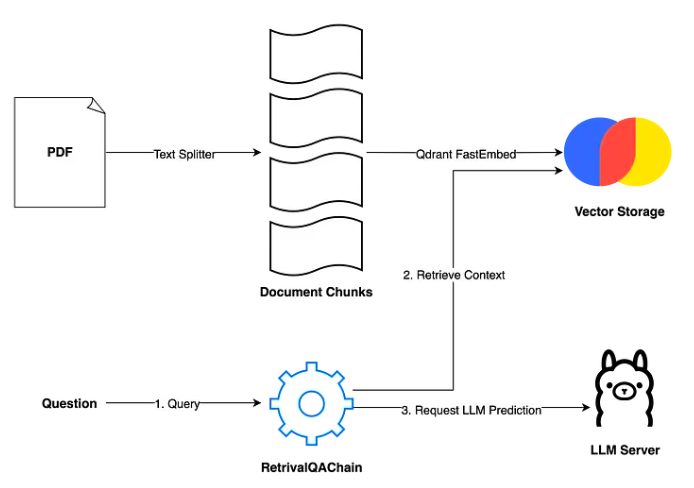
The RAG-based chatbot operates through a well-defined pipeline, ensuring efficient processing and retrieval of information. Below is a detailed breakdown of the pipeline:
Text Splitting:
- Input: The pipeline begins with a PDF document.
- Process: The document is processed using a Text Splitter, which breaks it down into manageable chunks. These chunks represent smaller segments of text, making the subsequent processing more efficient and accurate.
Vector Storage:
- Embedding: Each document chunk is transformed into a high-dimensional vector using Qdrant FastEmbed. This embedding process captures the semantic meaning of the text, allowing for effective similarity searches.
- Storage: The generated vectors are stored in a Vector Storage system, which facilitates quick retrieval of relevant chunks based on user queries.
Retrieval and Contextualization:
- Query Handling: When a user submits a question, the query is processed through the RetrievalQAChain.
- Context Retrieval: The system retrieves the most relevant document chunks from the Vector Storage based on the semantic similarity to the user’s query.
- Contextual Combination: The retrieved chunks provide the context needed for the next stage, ensuring that the response is grounded in the document’s content.
LLM Prediction:
- Request Handling: The contextual information is sent to the LLM (Large Language Model) Server.
- Response Generation: The LLM Server processes the context and generates a precise, contextually appropriate response to the user’s query.
- Output: The final response is delivered to the user, effectively answering their question with high accuracy and relevance.
Technologies Used
Technologies Used in the RAG-based Chatbot Code
1. Python
2. PyMuPDF (Fitz)
3. Langchain
4. FAISS (Facebook AI Similarity Search)
5. Hugging Face Embeddings
6. Ollama API
Conclusion
Our RAG-based chatbot represents a significant advancement in the field of information retrieval and conversational AI. By integrating robust document chunking, advanced vector storage, and powerful language models, the chatbot provides users with quick, accurate, and contextually relevant responses to their queries. This project showcases our commitment to leveraging cutting-edge technology to enhance user interactions and deliver exceptional value.
For more information on how aiblux can help you with custom software solutions, contact us or explore our services.